AIC - Block Prediction
After the image has been converted to the YCbCr color space (for color images), the image is split into blocks of 8x8 pixels. These blocks are encoded in scan line order, that is, from left to right and from top to bottom. While decoding the image, the decoder has access to all previously decoded blocks: all blocks above the current block and all blocks to the left of the current block in the current scan line. The following figure shows how an image is divided into blocks. The light green block is the current block and the light blue blocks are previously encoded/decoded blocks.
AIC uses a block prediction scheme borrowed from the H.264 standard to predict the contents of the current block from previously encoded and decoded blocks. H.264 has algorithms to predict 4x4 and 16x16 blocks. AIC uses the 4x4 algorithms, extended to the 8x8 block case. When predicting the contents of a block, AIC uses up to 25 pixels from previously encoded/decoded blocks to make the prediction. The following figure shows the current 8x8 block and these 25 pixels:
Prediction Modes
AIC and H.264 support 9 prediction modes:
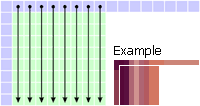 |
Mode 0: Vertical The upper pixels are extrapolated vertically. |
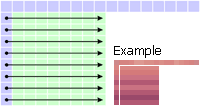 |
Mode 1: Horizontal The left pixels are extrapolated horizontally. |
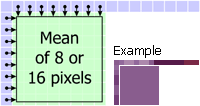 |
Mode 2: DC The mean of the upper and left samples is used for the entire block. If the upper samples are not available, only the left samples are used. If the left samples are not available, only the upper samples are used. If both left and upper samples are not available (first block in the image), the value 128 is used (50% gray). |
 |
Mode 3: Diagonal Down-Left The pixels are interpolated at a 45° angle from the upper-right to the lower-left corner. |
 |
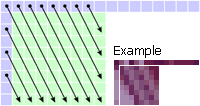
Mode 4: Diagonal Down-Right The pixels are interpolated at a 45° angle from the upper-left to the lower-right corner. |
 |
Mode 5: Vertical-Right The pixels are interpolated at a 26.6° angle from the upper-left corner to the lower edge at half the width. |
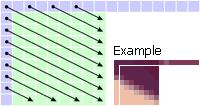 |
Mode 6: Horizontal-Down The pixels are interpolated at a 26.6° angle from the upper-left corner to the right edge at half the height. |
 |
Mode 7: Vertical-Left The pixels are interpolated at a 26.6° angle from the upper-right corner to the lower edge at half the width. |
 |
Mode 8: Horizontal-Up The pixels are interpolated at a 26.6° angle from the lower-left corner to the right edge at half the height. The pixels in the bottom-right corner cannot be predicted from lower pixels, since these pixels have not yet been encoded/decoded yet. These pixels are set to the bottom-most available previously decoded pixel. |
A prediction mode may only be used if all the pixels needed for prediction are available. For example, the Vertical mode may only be used when the upper samples are available, thus when the current block is not in the first row of blocks. The exception to this rule is the DC mode, which is the only mode that can be used for all blocks. This mode only uses the available pixels to calculate a mean. When no pixels are available (which is the case for the first encoded block), the value 128, or 50% gray, is used.
For more details on how these prediction modes are implemented in the AIC software, see the Block Prediction Implementation Details page.
The AIC encoder tries all 9 prediction modes for every block in the luminance (Y) channel. The prediction mode that minimizes the differences between the predicted block and original block is than used for prediction. The chosen prediction mode must be encoded in the stream. To save bits on encoding the prediction modes for the chominance (Cb and Cr) channels, these channels use the same prediction mode as the corresponding block in the Y channel. Since the chrominance channels usually have the same gradient directions as the luminance channel, they can be predicted with the same modes as the luminance channel. To further reduce the number of transmitted bits, the prediction mode itself is predicted from previously used prediction modes. When the prediction is correct, only 1 bit (actually 1 symbol) has to be encoded to indicate that the predicted prediction mode must be used. Only for false predictions, must the prediction mode itself be encoded.
For a result of this prediction process, look at the Lena image (again) below:
 |
 |
Original Lena image |
Predicted image |
As you see, the first block of every predicted image contains 50% gray pixels since this is the only block that cannot be predicted from previous blocks. The DC mode is used for this block. When good prediction modes are chosen, the predicted image shows much resemblance with the original image. In that case, the differences between the predicted and original image are low, so they will compress very well.
Note that both encoder and decoder need exactly the same pixels to base the prediction on. That's why the encoder also decodes every encoded block so both encoder and decoder have the same blocks to use for prediction. In other words, the predicted blocks are always predicted from previously decoded blocks.
Residual Blocks
The values in the predicted block are subtracted from the ones in the original block to form a residual block. As said before, when good prediction modes are chosen, these residual blocks will contain small values. The following image shows the differences between the luminance channel of the original Lena image and the predicted image:
 |
Residual Luminance image |
In this image, 50% gray areas represent zero-values where the predicted image is the same as the original image. Lighter and darker areas represent the errors between the original and predicted image. This image is "very gray", which means that the errors are usually small.
In the next step, each residual block is transformed using the Discrete Cosine Transform and Quantised, making the values in each block even smaller.